C’è una interessante convergenza in atto tra l’industry degli smartphone e quella della ricerca in AI. La prima, spinta da una concorrenza mai doma, cerca di infarcire sempre di più di gadget i dispositivi che un tempo utilizzavamo per telefonare. Fungendo da volano per mondi limitrofi, si pensi all’evoluzione negli schermi di cui hanno poi beneficiato i televisori, o a quello dell’ottica digitale, con obiettivi miniaturizzati supportati da chip DSP di alto livello che fanno ormai concorrenza al mondo della fotografia prosumer.
La seconda, la ricerca accademica, si ritrova piacevolmente strangolata tra la necessità di raccogliere finanziamenti (magari proprio strizzando l’occhio al mondo consumer) e quella di elaborare la micidiale mole di dati che ormai esce dalle mani virtuali di ogni cittadino del mondo.
Prendiamo ad esempio proprio il mondo della fotografia digitale. Da semplici obiettivi dotati di miseri 2MP siamo velocemente passati a 12, 20, 40MP, in una configurazione magari ad ottica doppia, in grado di fare da tele, grandangolo e sfocare lo sfondo. Una marea di dati, insomma, brodo primordiale per far nascere “qualcosa” che sia AI-driven.
Micidiale è la tecnica 3d photo inpainting di Meng-Li Shih et al. che mira a ricostruire una scena pseudo 3d sulla base di una semplice foto bidimensionale. Il loro algoritmo riesce ad analizzare la foto, cogliere la profondità, scomporre in piani di profondità, costruire un modello 3D e navigarlo tramite movimenti X,Y,Z. Incollo qui sotto un esempio a mio avviso sbalorditivo
Come funziona questo algoritmo, detto in parole povere (Se vi interessa, andatevi a leggere per intero il paper):
- l’immagine viene analizzata e raffinata per scoprirne i bordi. I bordi così ricostruiti vengono uniti tra loro in una (o più) singole unità logiche, gli “oggetti”
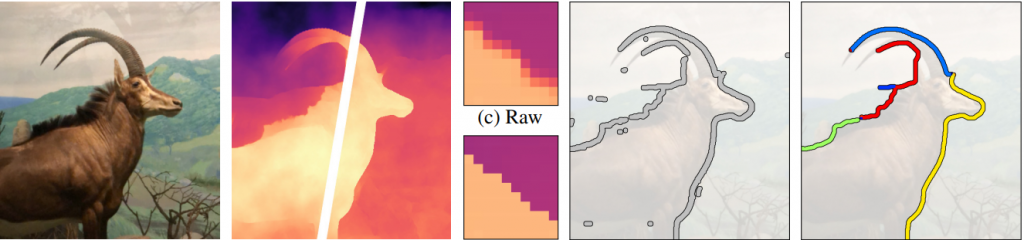
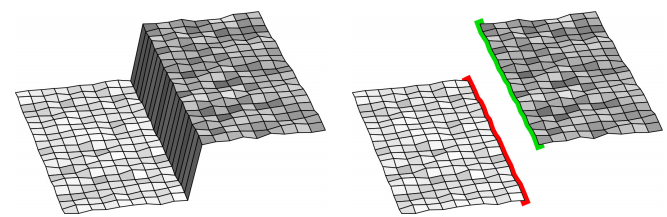
2. gli oggetti vengono “tagliati” in corrispondenza delle linee di bordo, andando a costruire piani di profondità diversi
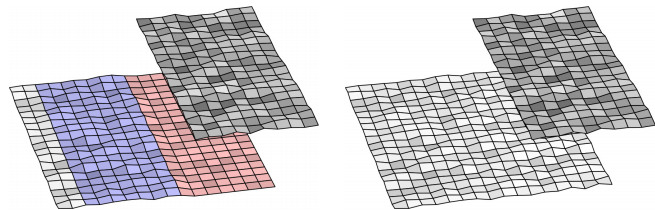
3. Qui arriva la vera magia: la parte nascosta dei livelli di sfondo viene ricostruita artificialmente analizzando la texture disponibile.
4. La scena è a questo punto composta da una serie di livelli uno posto dietro l’altro e può essere navigata in 3d da una telecamera virtuale.
Osserviamo ad esempio con attenzione quest’altro esempio. Nella foto originale, la porzione di luna posta dietro alla schiena dell’astronauta non è mai stata fotografata, perché eclissata dall’astronauta stesso. L’algoritmo cerca proprio di ricostruire il possibile aspetto della superficie lunare mancante, imparando a conoscerla tramite le porzioni visibili e cercando di “indovinare” come potrebbe essere fatta quella non visibile.
Se vi è venuta voglia di giocare un po’ con questa tecnologia, gli autori hanno reso tutto il lavoro disponibile nel repository di Google Collaboration accessibile qui.
Dove queste tecnologie ci porteranno non è del tutto chiaro, ma alcune implicazioni già le possiamo intravedere. l’AI (opportunamente addestrata) riesce ad aggiungere quel pizzico di “intelligenza umana” alla tecnologia, andando a ricostruire le informazioni mancante sulla base dell’esperienza.
Se ci pensiamo, è esattamente quello che il nostro cervello fa tutto il giorno: ci bastano frammenti di informazione per ricostruire il tutto. La capacità di ricostruire si basa essenzialmente sull’esperienza precedente. Se di un volto vedo solo un occhio, posso saldamente poggiare sulla quasi certezza che ce ne sarà un secondo e che sarà di forma/colore molto simile a quello che posso osservare.
Noi umani siamo tremendamente bravi a compiere questo tipo di operazioni, e le macchine stanno iniziando ad imitarci. Ma non credo sia realmente questo il fine ultimo della ricerca in questo ambito: mi sembra evidente che il gioco più interessante sia proprio al di fuori dell’ambito di applicazione umano.
Cosa succederà, infatti, quando una macchina, brava quanto noi nel riconoscimento visivo, potrà essere utilizzata su ambiti diversissimi, come ad esempio il riconoscimento di pattern di fenomeni al momento totalmente incomprensibili?
Il nostro cervello si è evoluto appositamente per analizzare i cinque sensi e su di essi è (al momento) il primo della classe. Nell’ambito sensoriale siamo capaci di gestire milioni di informazioni al secondo, competendo senza problemi con un intero centro di supercalcolo. Ma non è così quando dobbiamo analizzare aspetti di logica o di statistica. In questo caso non possiamo poggiare su un supporto “hardware” scolpito nella nostra ROM evolutiva.
Dobbiamo necessariamente eseguire un “software” nella memoria RAM volatile, con performance molto scadenti, e possibilità di ricordare solo un numero incredibilmente basso di passaggi.
Ma per una AI che avrà imparato a vedere il mondo con i nostri occhi, sarà un passaggio immediato e spontaneo quello verso altri contesti. Probabilmente spalancandoci la vista verso interpretazioni, concetti, analisi e conseguenze, che non avremmo mai potuto neppure immaginare.

